
The growing adoption of generative artificial intelligence, machine learning and high-performance computing across various industries has dramatically increased the demand for advanced graphics processing unit computing resources in the last two years. This has created a need for GPU cloud infrastructure that the hyperscalers cannot fully serve currently, due to volume of demand and velocity of GPU availability.
GPU-as-a-service (GPUaaS) providers specializing in cloud-based GPU resources have stepped into the breach. These companies differentiate their offerings from the hyperscalers by delivering built-for-purpose GPU infrastructure that can scale as required, offering more attractive pricing and configuration options, and providing an infrastructure tailored to service high-intensity AI workloads.

It is still early in the AI journey, given OpenAI LLC's ChatGPT 3.5 rocked the world just 18 months ago. This market is forecast to grow exponentially, and horizontal and vertical offerings are set to evolve in rapid order with a plethora of AI products. These specialized AI applications span industries and address a broad range of problems, from AI apps in the core and at the edge to embedded AI within consumer devices. The technology will proliferate quickly, moving beyond model creation and testing to inferencing operational execution. It will continue to expand and consume more GPU compute resources for years to come.

Context
Some of the GPUaaS providers originated from crypto/bitcoin mining endeavors and pivoted to the GPU cloud services opportunity. Others started in high-performance computing (HPC) offerings and AI research and evolved their own infrastructure requirements, high-performance capacity and experience into the business of on-demand GPU sales and large language model (LLM) training, deployment and operation. When enterprises need cutting-edge GPU processing capabilities and the ability to use many thousands of GPUs concurrently without restrictions, especially for training LLMs and operating these models at scale in the cloud, then GPUaaS presents a viable alternative to the traditional cloud providers.
While LLM training will largely happen in the cloud, enterprise deployment may be mixed in terms of in the cloud versus on-premises, because some companies are pursuing on-premises GPU deployment in recognition of security and cost concerns. However, high-performance GPU availability and cost issues — coupled with the fact that enterprises are in a cloud frame of mind (having adopted the cloud operating model and recognized its operational versus capital expenditure tradeoff and dynamic scaling benefits) — portend more GPU renting than buying. Additionally, companies have already invested in developing the in-house expertise to leverage public cloud deployments and operation.
GPU availability is becoming a serious concern for many companies. Where AI is deployed will be influenced by several factors, but costs, and securing sensitive and confidential data, will have an impact on determining the venue for AI training and model operation. Even as enterprises set their sights on cloud deployment, they face the challenge of rapidly diminishing cloud resources, with both traditional hyperscalers and GPUaaS providers quickly selling available capacity. Moreover, procuring the most advanced GPUs is becoming increasingly difficult for enterprises, given the availability of chips, as well as demand from cloud providers and their preferential purchase power.
Investment
The current market urgency for GPU resources to advance AI deployment and operation, along with the shortage of high-performance GPUs, is driving significant investment in and utilization of GPUaaS providers. To build out immense datacenter capacity requires large amounts of new capital. In the last two years, a few GPUaaS companies have raised significant amounts in investment and debt.
CoreWeave Inc. raised $8.6 billion in the last quarter. In the first four months of this year, Lambda Labs raised $820 million. From August 2023 to May 2024, CoreWeave raised $9.8 billion in debt, while $500 million of Lambda Labs capital raised this year was debt. Very large investments have been made in the belief that this is a rapidly expanding market with tremendous potential.

Technology
Servicing these AI/ML demands does not require the hyperscalers' plethora of services, so GPUaaS providers have focused on scaling up GPU availability, scaling out specialized infrastructure to support concurrent GPU workloads, and providing the orchestration tools for deployment and operation of GPU-hungry applications. GPUaaS companies have brought online the datacenters and tools for customers to deploy and scale AI applications, from small numbers of GPUs to tens of thousands. These companies are putting their GPUs under contract as quickly as they can add additional capacity — they do not build out hoping customers will come, customers are already there and requesting more.
GPUaaS providers are an attractive sales opportunity for GPU chip providers because they are exceptionally GPU-hungry, and are not actively developing competitive chips. By contrast, Amazon Web Services Inc. has developed the Inferentia and Trainium chips, while Google LLC recently launched its Axion Arm-based CPUs for improved cloud and AI performance. Microsoft Corp.'s Azure Maia AI chip and Arm Holdings PLC-powered Azure Cobalt CPU arrive in 2024.
All of this silicon will compete with chip manufacturers' own GPU products. One interesting twist here is NVIDIA Corp.'s DGX cloud. The company has deployed and is selling its own GPU cloud with the NVIDIA stack for AI development, which is hosted by the hyperscalers. This is creating an interesting dynamic of cooperation/competition across all the players.
Key GPUaaS benefits
– Project scalability. Users can adjust GPU resources based on project requirements, deploying massive training jobs then scaling back to the required inference processing capacity. In the cloud environment, runtime capacity can dynamically scale up or down in near real time based on demand.
– Cost efficiency. GPUaaS, like all cloud operating models, enables organizations to completely avoid the up-front capital expenditure investments in hardware and the operational expenses associated with owning physical infrastructure, including deployment and operational energy costs for equipment and cooling.
– Cost elasticity. The pay-as-you-play model of the cloud enables organizations to only incur operating expenditure costs as required to service actual workloads at execution, and only to pay for the resources activated. This allows total control of dynamic resource allocation, with the only limitations being company budget and provider capacity. It also enables continuous access and dynamic upgrades to the latest and greatest hardware with no capex or depreciation schedule on the balance sheet.
– Operational elasticity. GPUaaS providers supply multiple GPU configurations selectable at runtime to accommodate various use cases, such as deep learning training or inference tasks and budgets. This enables companies to choose GPU architecture for specific AI training and operation workloads to take advantage of the reduced training time and cost/performance improvements of new advanced GPUs.
– Performance tuning for specific stacks and models. For organizations not inclined to manage infrastructure, serverless options provide a number of benefits, such as immediate access to pretrained models; easy model customization and new LLM uploads; fast cold start for rapid launch; scale-to-zero to minimize cost when a model is not being accessed; and fast, easy automatic scaling (as long as the infrastructure has capacity).
– Faster time to market. The cloud allows for rapid prototyping and deployment by granting immediate access to cutting-edge technology, so no waiting on the procurement and installation of hardware. GPUaaS providers also have the advantage of having built a cloud fabric designed for the rigorous technical requirements of parallel workload execution to service concurrent GPU workloads.
GPUaaS concerns
– Data security. Cloud providers typically employ robust security measures to ensure the protection of sensitive information, and adhere to strict compliance standards. Enterprises are concerned, however, about protecting their assets.
– Latency and performance. Although GPU services are typically built for high performance, network latency can impact overall performance for certain operational data access paradigms, when compared with an on-premises deployment that has direct access to hardware and data stores.
– Integration and compatibility. A crucial aspect of selecting a GPUaaS provider is ensuring compatibility with current tools, frameworks, ML libraries and workflows to deploy and operate workloads in the cloud. Additionally, companies must consider the level of difficulty to integrate the GPUaaS platform into existing infrastructure because some providers have more mature APIs and comprehensive documentation with example code.
– Price premium. High-performance GPUs are expensive to rent. The classic cloud business model applies in terms of how many hours will be consumed and whether the optimal financial model is rent versus own.
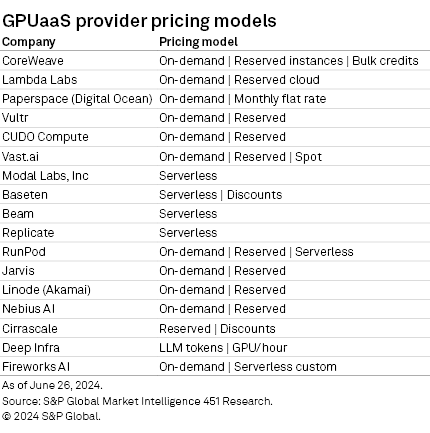
Pricing models
Almost all of GPUaaS providers provide an on-demand price and a reserved price, and several use or provide a serverless infrastructure option for LLM deployment and orchestration, with customers paying only for tokens or container operation. Reserve pricing policies differ, and customers will need to pay attention to the actual deployment and operating costs as billing varies for execution time, idle time, memory, virtual CPUs, storage, network, and the other nuances of deployment and operation depending on the vendor.
Conclusion
The specialized GPU cloud provider market is rapidly evolving, driven by an ever-increasing demand for generative AI, AI/ML and HPC capabilities. Enterprises are finding that the traditional IaaS offerings are not optimized to train and operate AI applications and deploy GPUs at the scale now required.
A number of GPUaaS providers, such as CoreWeave, Lambda Labs, Vultr Holdings Corp. and Paperspace, are at the forefront of this transformation, each with unique strengths and market focus. As GPU demand grows, these providers will continue to expand their infrastructure, customer base and revenue, impacting the market and influencing how companies deploy and operate AI workloads. 451 Research will continue to follow this market and will publish additional research in the months ahead.
This article was published by S&P Global Market Intelligence and not by S&P Global Ratings, which is a separately managed division of S&P Global.
451 Research is a technology research group within S&P Global Market Intelligence. For more about the group, please refer to the 451 Research overview and contact page.