
Download The Full Report
Click HereUnstructured data1 is largely underexplored in equity investing due to their higher costs2. The information content, as a result, remains largely untapped and offers an investment edge3 to discerning investors who are adept at extracting those investment insights. One particularly valuable unstructured data set is S&P Global Market Intelligence’s machine readable earnings call transcripts.
This newest publication, the third in the series (NLP I, NLP II), introduces new stock selection ideas in the areas of I) Topic Identification, II) Call Transparency and III) Call Sentiment using more advanced NLP techniques. The new signals complement the existing suite of signals that is offered in our Textual Data Analytics (TDA)4 product, an off-the-shelf NLP solution for both quantitative and fundamental analysts. The high-level U.S. findings are:
Exhibit 5: MSFT’s October 26, 2017 Call Transcript - Executives’ Prepared Remarks & Q&A
Note: The exhibit contains five columns of binary flags, a subset of all available binary flags in the analysis.
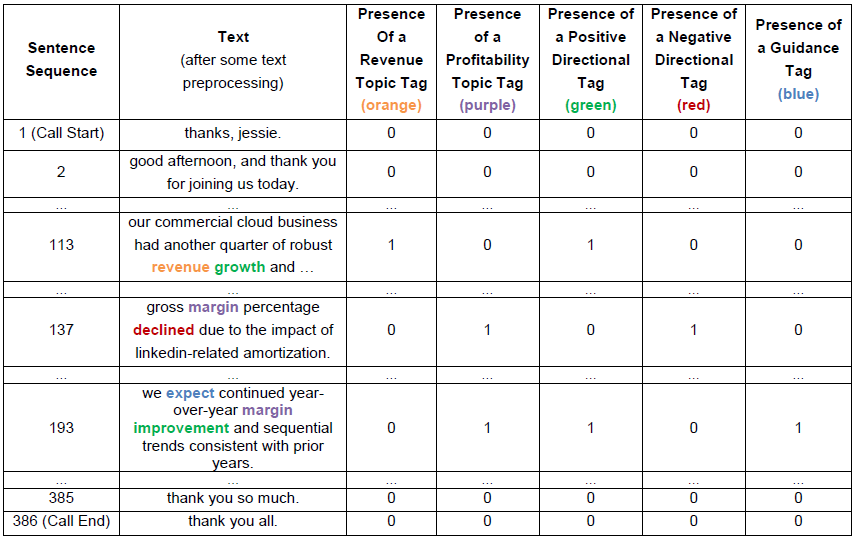
Source: S&P Global Market Intelligence Quantamental Research, as of 12/01/2019.
1 Unstructured data sets are non-numerical data sets such as texts, audios and images that are of primary source. Primary source data in this context i) are furthest up the information chain containing the most relevant and timely information, ii) are easily mapped to publicly traded firms and iii) have good historical and cross-sectional coverage.
2 The exploration of non-numerical data sets requires more advanced technical infrastructure and tools. The exploration requires more time from researchers to vet the data. The probability of finding additive signals is lower.
3 Other examples may be more sophisticated modeling (e.g., non-linear) and execution efficiency.
4 See Section 5 Data & Methodology in paper for details.