
Introduction
A few insurers have applied machine learning techniques to ratemaking and gained regulatory approval to do so, based on a review of U.S. property and casualty product filings from 2019 to 2021. We expect more insurers to follow their lead, as the data science field progresses and regulators become more comfortable with machine learning approaches to statistical analysis.

Machine learning concepts have a reputation for complexity, with some labeled "black boxes" when a human cannot explain exactly how an algorithm is making decisions. This can pose difficulties for insurers in the ratemaking process, as regulators want an explainable model before they sign off.
That said, some machine learning techniques can improve statistical analysis without being too inscrutable. Our review of product filings from 2019 to 2021 found only a few insurers that included machine learning terms such as "k-nearest neighbors," "random forest" and "XGBoost." But that cadre of insurers had their filings approved, potentially paving the way for other insurers to follow.

Broadly speaking, machine learning refers to models that improve based on data fed to them. In essence, they learn and adapt with new information. Machine learning has the potential to meaningfully improve existing statistical models, and some techniques that were previously only theoretical are now possible due to cloud data storage and faster computer processing speeds.
Actuaries seem eager to use machine learning more often. Panelists and members of the audience at the 2022 Spring Meeting of the Casualty Actuarial Society held May 15-18 in Orlando, Fla., expressed interest in machine learning regularly during the event. Many machine learning concepts are included in the Modern Actuarial Statistics portion of the CAS exams and, in our view, incumbent insurance underwriters already have a deep bench of data science talent in the form of their actuarial team.
For our analysis of product filings, we conducted keyword searches in S&P Global Market Intelligence's insurance product filings database of three relatively distinct machine learning terms: "k-nearest neighbors," "random forest" and "XGBoost." "K-nearest neighbors" was the least popular, at three mentions in the three years in our analysis, while "XGBoost" was the most, at 15 in the same period.
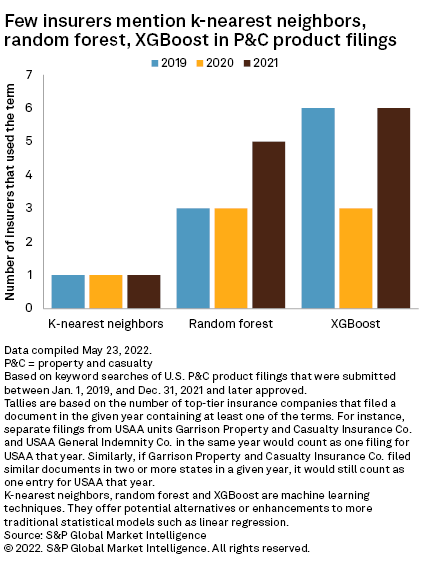
The k-nearest neighbors algorithm takes a new data point and compares it to a previously categorized data set, assigning the new data point to a category based on others like it. According to the product filings, the algorithm is useful to insurers for estimating a property's loss exposure when data is unavailable for that specific property. Filings from The Travelers Cos. Inc. and Liberty Mutual Holding Co. Inc. offer two examples.
A random forest model is fundamentally a decision tree model, which creates branches of a data set by splitting it into smaller and smaller categories based on significant variables. The "forest" part of random forest refers to the tree model being run repeatedly, potentially thousands of times or more. Like a Monte Carlo simulation, this might yield better results than a single tree model, as it finds an average value across many different runs.
Two auto-focused insurtech startups that rely on telematics, Root Insurance Co. and Just Auto Insurance Co. Inc., referenced random forests in their product filings. Root used a random forest model to develop factors for drivers, based on rating variables like the driver's age, the vehicle's age and the number of drivers of the vehicle. Just Auto mentioned how a data partner, Sentiance NV/SA, uses a random forest model to identify when drivers are handling their phones.
But insurtech startups were not the only ones using random forest models. GEICO Corp. and American Family Insurance Group — both large auto insurers with decades of operating history — each referenced random forest models in their filings. As these examples show, insurtech companies might not have a decisive advantage over incumbents in the use of machine learning, at least when it comes to ratemaking.
It is possible that insurtech companies have more sophisticated techniques and are filing them confidentially. But, if so, getting such models approved might be a challenge. For both GEICO and American Family, regulators wanted more information on their random forest models. In Illinois, regulators asked if a generalized linear model could be fit to GEICO's predictions to replicate the results of the random forest model — rather than providing all 800 decision trees. In Nevada, regulators asked American Family to provide information on the importance of the variables in its random forest model. In Montana, regulators asked XL Specialty Insurance Co. to provide Shapley additive explanations, or SHAP, plots, which can be used to explain a variety of machine learning models.
Explaining machine learning models is not just a goal of regulators. Many within the field of data science have recognized the need and created software to aid in the process. As the Montana regulators suggested, there is a function already available from the XGBoost package in the programming language R that will calculate Shapley values.
XGBoost is a popular software library for "boosting" statistical models. A boosting algorithm takes multiple existing models, tests them on the data set, then sees how the different models performed and assigns them weights. As our product filings analysis showed, XGBoost — or gradient boosting models, more broadly — can be used for a variety of lines. Insurers included the term in auto, homeowners, pet, livestock and mortgage insurance product filings.
Looking ahead
Based on the progression of the data science field, one of the next big frontiers for insurance product filings is likely neural networks. Neural networks have led to extraordinary advances in areas like natural language processing and image recognition, but our product filings analysis avoided the topic because the search results were too noisy. For instance, Ohio regulators ask insurers to describe the type of model used and offer "neural network" as an example, leading to many false positives.
In neural networks, the algorithm continuously assigns different weights to input data and tests to see which weights produce the best outcome. Neural networks might face a tough road with insurance regulators due to the current challenges in explaining them. The process starts with random assumptions and the model learns on its own, so the actuary might be at a loss to explain why the algorithm chose the weights it did and the connections it made to reach its conclusion.
But even if regulators reject neural nets, the approval of k-nearest neighbors, random forest and XGBoost techniques indicates to us that machine learning approaches are gaining greater acceptance. We expect that momentum to accelerate as other insurers follow in the footsteps of the early adopters.
This article was published by S&P Global Market Intelligence and not by S&P Global Ratings, which is a separately managed division of S&P Global.